Code sense
Mats Persson has been busy augmenting TextMate with a bundle for PHP function completions and other nice things like a tooltip to show function prototypes and similar.
I realize that the desire for language specific auto-completion (code sense) is high. So far I’ve held back on providing a proper (plugin) interface for this, since I do most of my work in C++, and here proper code sense requires a rather complete C++ parser, which is not easy to write (so I didn’t thought anyone would, even if I did provide the proper API).
But TextMate is a general purpose text editor and should not be held back just because C++ is overly complex to parse. So I’m currently working on a plugin API for plugins to show an unobtrusive completion menu below the text typed, here’s a picture (click for full size):
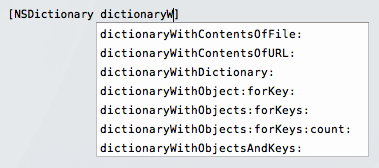
As the picture implies, I’m also working on the actual plugin for Objective-C/C++ (which is the hard part), I’m using ANTLR for this task. If you’re into writing parsers and feel like giving me a hand, please do :)
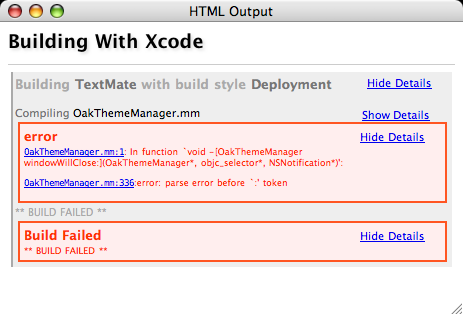
Oh… and just in case you’re following Steve Jobs advice and are moving to Xcode, remember that TextMate can (thanks to Chris Thomas) build Xcode project files with a very nice output. So just drag your project folder to TextMate’s application icon, open a source and press ⌘B followed by ⌘R (if there were no errors). There are also commands (by Chris) to import Xcode projects (located in the source bundle).
{kind=link}